![[기초통계학] 자료의 분류](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fc8a7jX%2FbtrEpAn8Dw6%2FiT4cbXKWmTETFQ9mCldAh1%2Fimg.png)
질적 변수와 양적 변수
질적 변수 (qualitative variable) --> 수량적
• 명목형 변수 (nominal variable)
- 구분이 목적. 순서/간격의 의미 없음
- 이진수 변수 (binary variable) : 두 개의 값만 취하는 명목변수
- 예) 성별 (M/F), 혈액형 (A/B/O/AB)
양적 변수 (quantitative variable) -> 비수량적
• 순서형 변수 (ordinal variable) [질적 변수일수도 있음]
- 구분/순서 의미 있음, 간격 의미 없음
- 범주형 변수에 해당하나 연속형 변수로 취급하는 경우도 있음
- 예) 선호도: Likert’s 5-point scale (라이커트의 5점 척도)
• 구간형 변수 (interval variable)
- 구분/순서/간격의 의미 있음. 절대 0 (true zero) 개념 없음
- 두 값 간의 비율이 유지되지 않음
- 예) 온도, 시간, 연도 등
• 비율형 변수 (ratio variable)
- 구분/순서/간격/절대 0의 개념 있음
- 변수 구간 내 비율 유지됨
- 예) 길이, 속도, 부피, 나이, 키, 몸무게 등
(구간형 변수와 비율형 변수를 굳이 구분할 필요 없으며 (일단은) 둘 다 연속형 변수로 간주하면 됨)
연속형 변수와 이산형 변수
연속형 변수 (continuous variable)
• 주어진 실수 구간 내의 모든 값들을 취할 수 있는 변수
• 좀 더 광의의 의미로 수치형 변수(numeric variable)라고도 함
• 연속적인 실수 값을 가지는(수로 표현될 수 없는 값을 가지는) 변수
이산형 변수 (discrete variable)
• 주어진 구간 내에 있는 특정 값만을 취하는 변수
• 주로 자연수, 정수 등의 계수자료(count data)
• 정수로 표현되면 범주형 변수(categorical variable)
• 두 범주이면 (즉, 두 개의 값만 취하면) 이진 변수(binary variable)
독립변수와 종속변수
독립변수 (independent variable) = 설명변수 (explanatory variable)
인과관계가 존재하는 경우, 원인에 해당하는 변수 --> 영향을 주는 변수
y = a*x + b
종속변수 (dependent variable) = 반응변수 (response variable)
인과관계가 존재하는 경우, 결과에 해당하는 변수 --> 영향을 받는 변수
y = a*x + b
인과 관계
두 변수간 인과 관계를 나타낸 모델로써 화살표가 독립변수 X에서 시작하여 종속변수 Y에게 영향을 미치고 있다. 여기서 독립변수가 원인변수가 되며, 종속변수가 결과변수에 해당한다.
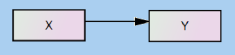
상관 관계
두 변수간 인과관계는 없지만 상관이 있는 모델이다. 어느 변수가 독립변수인지 종속변수인지 알 수 없는 모델이다.

'Data Science > 데이터분석' 카테고리의 다른 글
| [기초통계학] 통계적 추정 (0) | 2022.06.16 |
|---|---|
| [기초통계학] 표본평균의 분포와 중심극한정리 (0) | 2022.06.16 |
| [기초통계학] 확률분포 (0) | 2022.06.16 |
| [기초통계학] 대표값 (0) | 2022.06.16 |
| [기초통계학] 통계학이란? (0) | 2022.06.10 |